Although privacy activists are scared by the very thought, smart speaker developers are on a quest to allow their speakers to work even without hearing their wake term. We know that Google is working on this technology now, so now, the people at Carnegie Mellon University are following suit.

A machine learning algorithm has been developed by university researchers that uses the power of AI to decide exactly what direction someone’s voice comes from.
This may not seem very important at first, but the researchers in question are planning ahead for a future in which IoT devices become “increasingly dense” throughout home and office environments.
BY CORONAVIRUS-COVID19 SMART MEDICAL DEVICES MARKET
Imagine if you had a smart TV, speaker, and smartphone powered by Alexa all in one place. For any single one of them, speaking the wake word might very well trigger command mode, which is hardly necessary.
You would like to talk to one single smart device in such a situation, not a whole room full of them — that’s where this study comes into play. This approach to wake word-free commands differs from others in that facial recognition software, which may be for the better, is not needed.
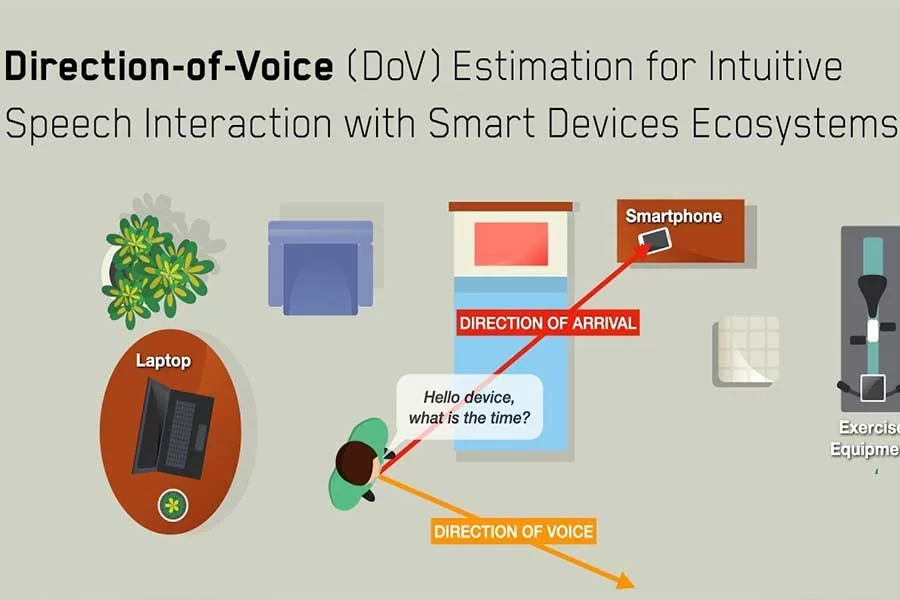
Naturally, this system’s accuracy will heavily rely on the average user’s ability to adapt to the concept. Users would suddenly need to ensure they aren’t accidentally talking in the general direction of a smart device when asking a question to a family member or friend, for example.
Google Says the Nest Safe Has Been Discontinued
However, that’s a problem for another day. This technology won’t even be rolling out to the general public any time soon (though the underlying code is open to all), so focusing on
About The Author
Hassan Zaka
I am an expert in accounting and possess diverse experience in technical writing. I have written for various industries on topics such as finance, business, and technology. My writing style is clear and simple, and I utilize infographics and diagrams to make my writing more engaging. I can be a valuable asset to any organization in need of technical writing services.
Follow Us:LinkedinTwitter